NVIDIA CUDA C¶
Abstract
GPU 编程原理与 NVIDIA CUDA C 编程实验
GPU 编程原理¶
CPU vs. GPU¶
- CPU :
-
- 少量且复杂的核心
- 低内存延迟的缓存(cache)较大
- 内存大但慢
- GPU :
-
- 大量简单核心
- 低内存延迟的缓存(cache)较小
- 内存小但快
CUDA 编程模型 vs. 硬件执行模型¶
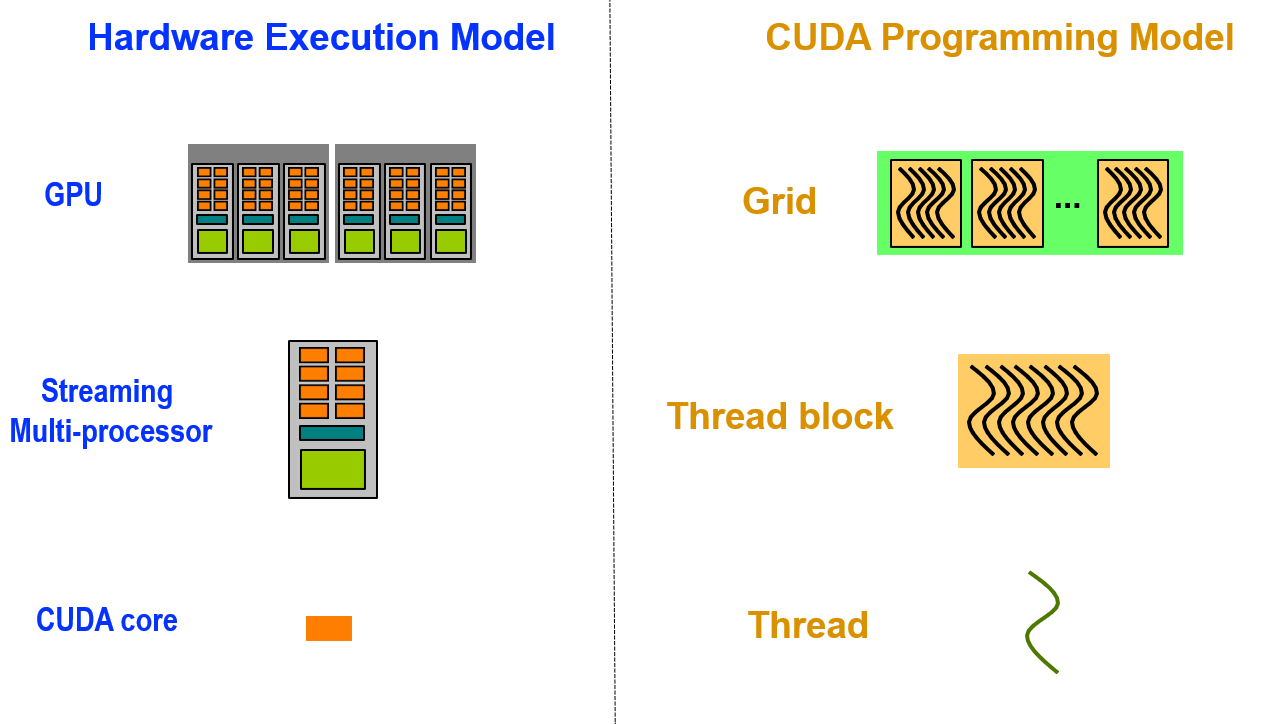
体系结构类别和编程模型¶
- SISD(Single instruction, single data)单指令流单数据流:传统的串行计算机。
- SIMD(Single instruction, multiple data)单指令多数据流:AVX、SSE 等指令集。
- SPMD(Single program, multiple data)单程序多数据流:对问题进行分解,再进行并行求解。
前两个是体系结构类别,最后一个是编程模型。
CUDA C/C++ 编程¶
由 NVIDIA 深度学习培训中心 (DLI) 提供的课程,在由 NVIDIA 提供的云环境上进行实验。
使用 CUDA C/C++ 加速程序¶
加速系统¶
加速系统又称异构系统,由 CPU 和 GPU 组成。加速系统运行 CPU 程序,由这些程序调度运行于 GPU 上的函数,通过 GPU 实现函数的并行计算。
查询 GPU 信息命令:
1 | |
GPU 加速原理¶
一个简单的 GPU 加速应用程序执行过程:
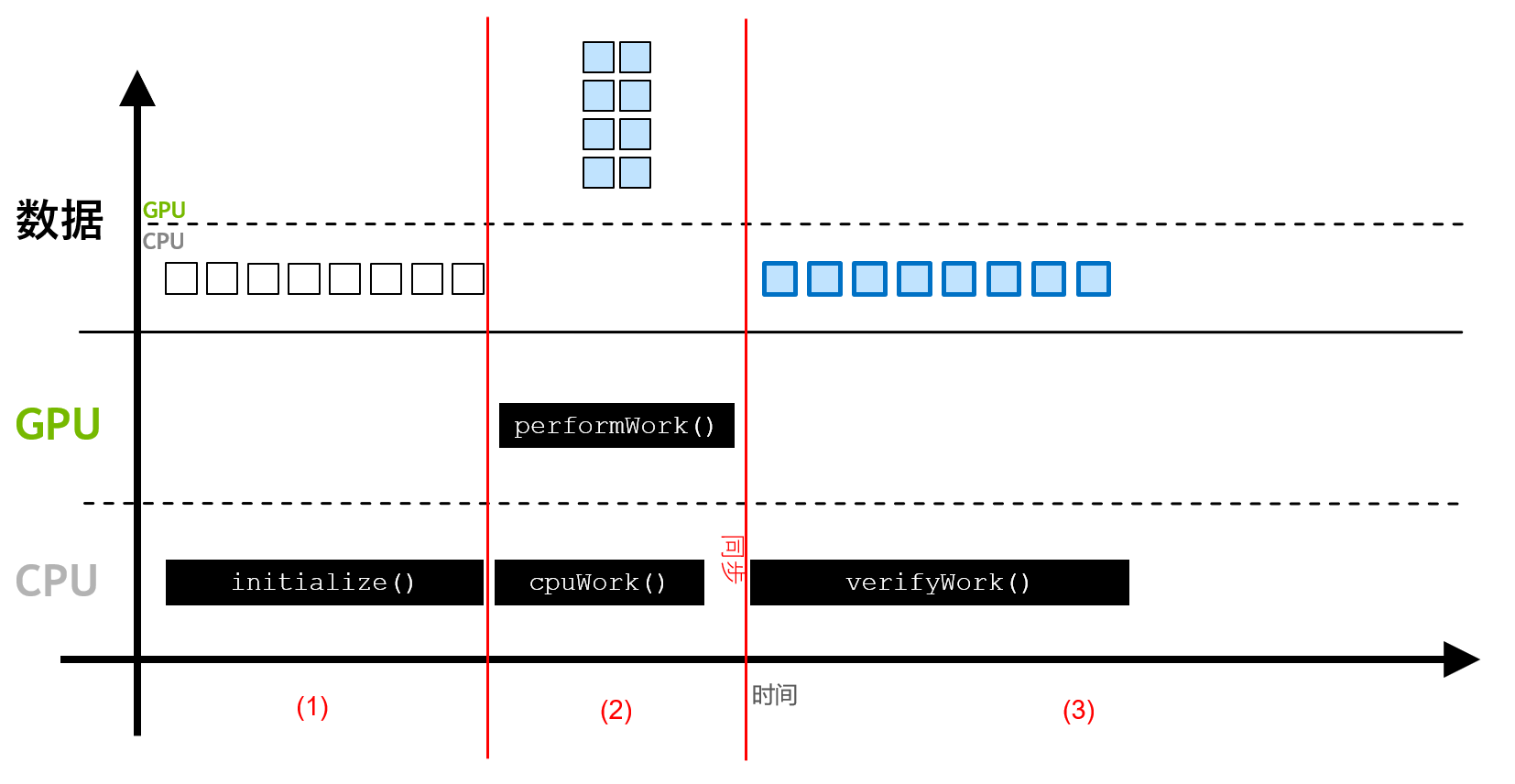
(1)段:数据由cudaMallocManaged()函数分配,并能由 CPU 访问处理。(2)段:数据可被迁移至可执行并行工作的 GPU ,并由 GPU 核函数访问,同时 CPU 可继续执行工作(异步执行)。- 通过
cudaDeviceSynchronize(),将 CPU 与 GPU 的工作同步。 (3)段:经 CPU 访问的数据迁移回 CPU。
GPU 加速应用程序编写¶
CUDA 加速程序文件扩展名为 .cu ,一个简单例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
一些语法:
__global__ void GPUFunction()
__global__关键字表明以下函数将在 GPU 上运行并可 全局 调用。- 通常,将在 CPU 上执行的代码称为 主机 (Host) 代码,而将在 GPU 上运行的代码称为 设备(Device) 代码。
- 使用
__global__关键字定义的函数需要返回void类型。
GPUFunction<<<1, 1>>>();
- 通常,当调用要在 GPU 上运行的函数时,将此种函数称为 已启动 的 核函数 。
- 启动核函数时,必须提供 执行配置 ,即在向核函数传递参数之前使用
<<<number_of_blocks, threads_per_block>>>语法完成配置。 - 在宏观层面,可通过执行配置为核函数启动指定 线程层次结构 ,从而定义线程组(称为 线程块 )的数量
number_of_blocks,以及要在每个线程块中执行的 线程 数量threads_per_block。如样例代码中,使用了包含1线程的1线程块启动核函数。
cudaDeviceSynchronize();
- 核函数启动方式为 异步 :CPU 代码将继续执行,无需等待核函数完成启动。
- 调用 CUDA 运行时提供的函数
cudaDeviceSynchronize使得主机 (CPU) 代码暂作等待,直至设备 (GPU) 代码执行完成,才能在 CPU 上恢复执行。
编译运行 CUDA 加速程序
使用 nvcc 命令编译和运行程序:
1 | |
nvcc为编译器命令。-arch选项指定架构类型。-o指定编译程序的输出文件。-run标志执行成功编译的二进制文件。
CUDA 线性层次结构¶
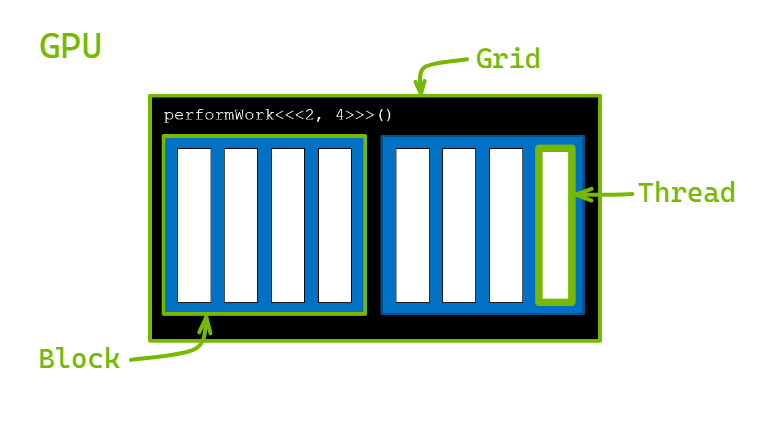
启动核函数时,核函数代码由每个已配置的线程块中的每个线程执行。
CUDA 提供了一系列线程层次结构变量:
gridDim.x网格中块数;blockDim.x每块中线程数。blockIdx.x当前线程所在线程块索引;threadIdx.x当前线程在线程块中的索引。
加速循环¶
步骤:
- 必须编写完成 循环的单次迭代 工作的核函数。
- 由于核函数与其他正在运行的核函数无关,因此执行配置必须使核函数执行正确的次数,例如循环迭代的次数。(注意:各个线程执行顺序不定,故可加速的循环需要各次迭代无关联且顺序无影响)
例子:
加速前:
1 2 3 4 | |
加速后:使用核函数实现单词迭代
1 2 3 4 5 | |
并调用
1 | |
此处必须有 number_of_blocks * threads_per_block >= N 。
分配内存¶
回忆一般的 CPU 程序分配并释放内存的方式:
1 2 3 4 | |
要分配和释放内存,并获取可在主机和设备代码中引用的指针,则需要使用 CUDA 提供的函数 cudaMallocManaged() 和 cudaFree() :
1 2 3 4 | |
其他一些用于手动内存管理的 CUDA 命令:
cudaMalloc命令将直接为处于活动状态的 GPU 分配内存。这可防止出现所有 GPU 分页错误,而代价是主机代码将无法访问该命令返回的指针。cudaMallocHost命令将直接为 CPU 分配内存。该命令可固定内存(pinned memory)或页锁定内存(page-locked memory)。允许将内存异步拷贝至 GPU 或从 GPU 异步拷贝至内存。但固定内存过多会干扰 CPU 性能,因此需避免无端使用该命令。释放固定内存时应使用cudaFreeHost命令。cudaMemcpy命令可拷贝内存。示例1 2 3 4
// 从 host 向 device 拷贝内存 cudaMemcpy(device_a, host_a, size, cudaMemcpyHostToDevice); // 从 device 向 host 拷贝内存 cudaMemcpy(host_a, device_a, size, cudaMemcpyDeviceToHost);
跨网格循环¶
当数据集比网格大的时候,可以使每个线程处理多个数据:
1 2 3 4 5 6 7 8 9 10 | |
错误处理¶
- 许多 CUDA 函数会返回类型为
cudaError_t的值,可用于检查调用是否出错。 - 为检查启动核函数时是否发生错误,CUDA 提供了
cudaGetLastError函数,返回类型为cudaError_t的值。 - 为捕捉异步错误(例如,在异步核函数执行期间),需要检查后续同步 CUDA 运行时 API 调用所返回的状态(例如
cudaDeviceSynchronize),如果之前启动的其中一个核函数失败,则将返回错误。
错误大致可分为同步错误 synError 和异步错误 asynError 。
对于 cudaError_t 值,将其与 CUDA 提供的 cudaSuccess 进行比较,即可判断是否出错,同时可以使用函数 cudaGetErrorString() 获得错误信息。
一个包装 CUDA 函数调用的宏:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
进阶内容 - 多维网格和块¶
可以将网格和线程块定义为最多具有 3 个维度, CUDA 提供 dim3 类型定义多维网格和块:
1 2 3 | |
在核函数中,可以使用 threadIdx.y 及类似形式获得相关索引和维度。
统一内存使用与使用 nsys 管理内存¶
nsys 使用¶
使用 nsys profile 分析编译好的可执行文件
$ nsys profile --stats=true ./test
nsys profile 将生成一个 qdrep 报告文件,使用 --stats = true 标志表示希望打印输出摘要统计信息。
流多处理器(Streaming Multiprocessors)¶
GPU 具有称为流多处理器(或 SM)的处理单元。在核函数执行期间,将线程块提供给 SM 以供其执行。SM 同时调度执行的线程块取决于 warp 大小(一般为 32)。
通常可以选择线程数量数倍于 32 的线程块大小来提升性能。
查询 GPU 属性¶
1 2 3 4 5 | |
props 中包含了 GPU 设备属性,主要用到 warp 大小 props.warpSize 。
统一内存(UM)行为¶
分配 UM 时,内存尚未驻留在主机或设备上。主机或设备尝试访问内存时会发生页错误(Page Fault),此时主机或设备会批量迁移所需的数据。同理,当 CPU 或加速系统中的任何 GPU 尝试访问尚未驻留在其上的内存时,会发生页错误并触发迁移。
稀疏访问数据时,触发页错误并按需迁移内存会有显著优势。
而需要大量连续的内存块时,通过异步预取内存可以有效规避页错误和按需数据迁移所产生的开销。
异步内存预取¶
CUDA 可通过 cudaMemPrefetchAsync 函数,将托管内存异步预取到 GPU 设备或 CPU:
1 2 3 4 5 6 7 | |
并发 CUDA 流¶
流是由按顺序执行的一系列命令构成。在 CUDA 应用程序中,核函数的执行以及一些内存传输均在 CUDA 流中进行。未作特殊声明的核函数在默认流中执行。
此外,程序可以创建非默认流,在不同的流中并发执行多个核函数。
默认流会阻止其他流中的所有核函数。当其他流中的所有核函数执行完毕之后,默认流中的核函数才开始执行;当默认流中的核函数执行完毕,其他流中的核函数才可以开始执行。
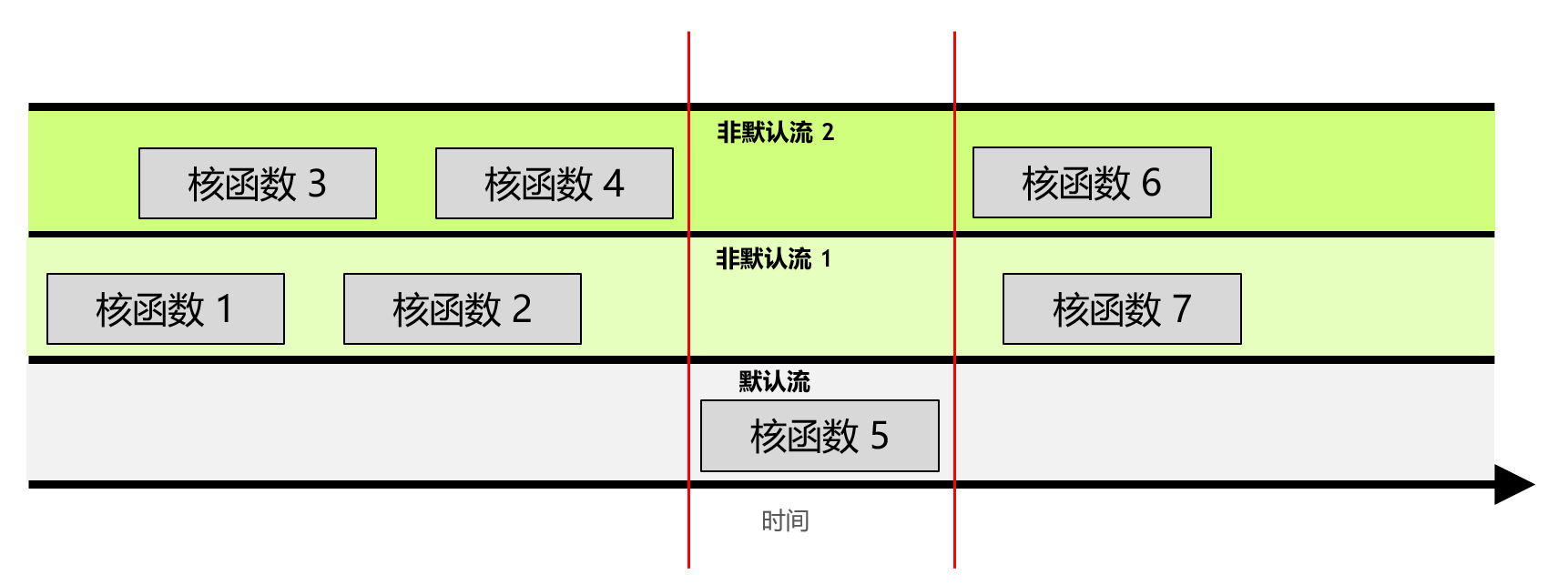
创建非默认流,并在非默认流中启动核函数:
1 2 3 4 5 6 | |