lab4 PCG Solver¶
实验步骤¶
访存优化¶
基准代码中,不连续的内存访问存在于对矩阵 A 对角线元素的访问中,通过将 A 对角线元素预先取出存放到连续的内存中,提高访存效率。
线程级并行(OpenMP)¶
使用 OpenMP 将循环并行化。
对于循环体之间无依赖的迭代,在循环前添加如下指令使其并行化:
#pragma omp parallel for schedule(static)
对于进行累加操作的迭代,使用归约 (reduction) 使其并行化(对 sum 进行累加):
#pragma omp parallel for reduction(+:sum) schedule(static)
并且使用 static 调度方式,使各个块包含的迭代次数平均。
进程级并行(MPI)¶
使用 MPI 开启不同进程进行并行计算。
整体思路为:根进程在计算开始前将矩阵 A 和数组 b 广播给各个进程,将 MatrixMulVec 函数中的矩阵与向量相乘运算分发给各个进程进行计算,计算完毕之后将各个进程结果进行合并并且广播,其余部分各个进程独立计算。
采用上述方式,尽量避免通信带来过大的开销,并且尽量加速时间消耗最大的矩阵与向量相乘运算。
源代码及 Makefile 文件位于当前目录下 pcg_c 文件夹内。
Note
其中 Makefile 文件进行了两处更改:
| Makefile | |
|---|---|
1 2 | |
使用 Intel 提供的编译器 mpiicc 。
根据官方文档,添加 -qopenmp 编译选项启用 OpenMP 。
使用 4 节点 8 任务对三组输入进行测试,使用 sbatch 提交如下脚本:
#!/bin/bash
#SBATCH -o out.txt
#SBATCH -N 4
#SBATCH -n 8
#SBATCH --exclusive
#SBATCH --cpus-per-task 12
source /opt/intel/oneapi/setvars.sh
ulimit -s unlimited
mpirun ./pcg input_2.bin | grep -v 'mpool' | grep -v 'ib_md'
结果分别用时 3.97 s 、17.48 s、91.90 s 。
Profile¶
以输入 input_2.bin 为例,使用 Intel Trace Analyzer and Collector 进行性能分析。

由图可得,耗时最多的三个 MPI 函数分别为 MPI_Allgather 、 MPI_Bcast 、 MPI_Comm_rank 。
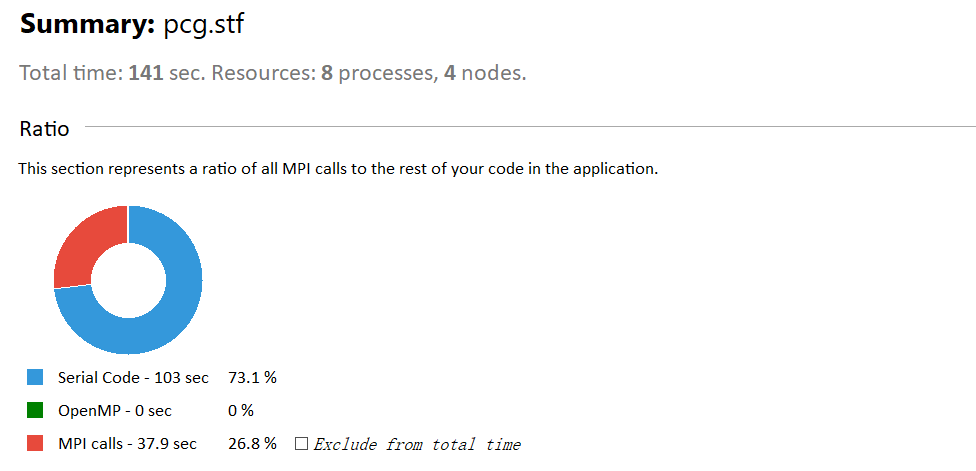
可得程序消耗的总时间为 103 s ,其中消耗在 MPI 上的总时间为 37.9 s 。
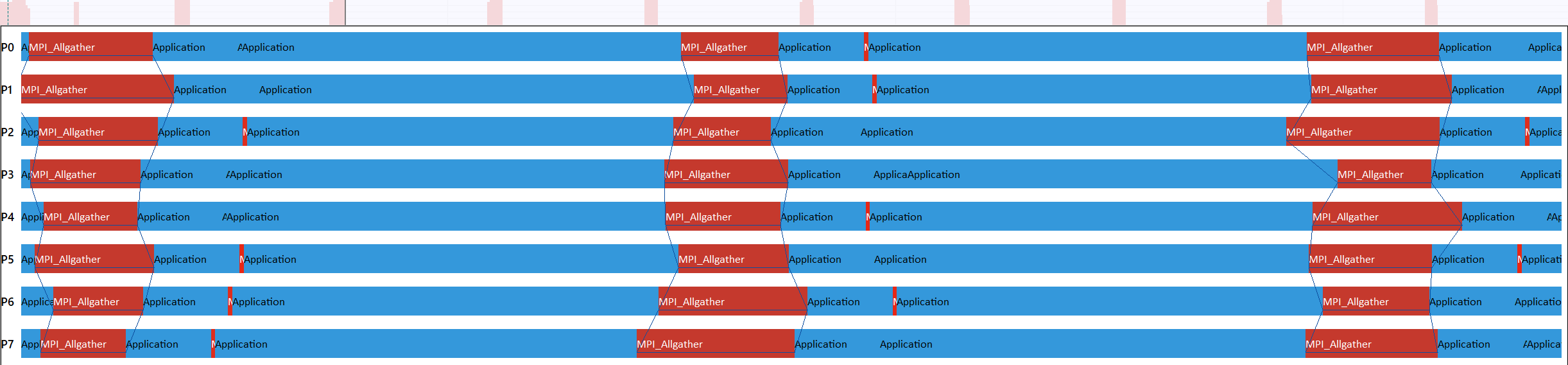
打开事件时间轴 (Event Timeline) 可以看到各个进程的运行情况:

由图可得,程序一共开启了 8 个进程,调用 MPI 的开销主要的位于每次进入 PCG 函数时调用 MPI_Bcast 函数。
截取一小段时间轴进行放大,可以得知在一次 PCG 函数的调用中,MPI_Allgather 函数被调用了多次:
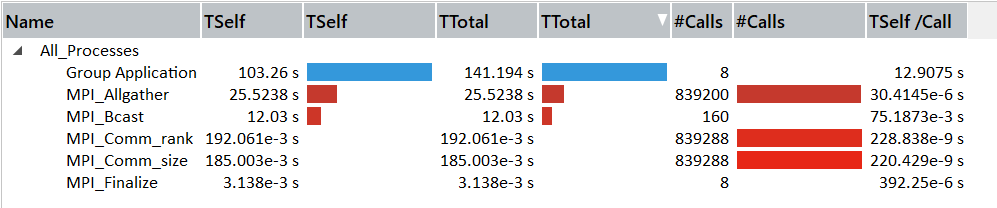
此外,右键下方的 Group MPI 选择 Ungroup MPI ,可以看到各个 MPI 函数的调用次数及时间消耗:
Bonus¶
使用 Fortran 完成实验。
源代码及 Makefile 文件位于当前目录下 pcg_fortran 文件夹内。
Note
Makefile 文件如下:
| Makefile | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
使用的 Fortran 编译器为 Intel 提供的 mpiifort 。
将 pcg.f90 、 main.f90 、 judge.c 分别编译汇编为 .o 文件后,再进行链接形成可执行文件 pcg 。
以使用 4 节点 8 任务对三组输入进行测试,使用 sbatch 提交如下脚本:
#!/bin/bash
#SBATCH -o out.txt
#SBATCH -N 4
#SBATCH -n 8
#SBATCH --exclusive
#SBATCH --cpus-per-task 12
source /opt/intel/oneapi/setvars.sh
ulimit -s unlimited
mpirun ./pcg input_2.bin | grep -v 'mpool' | grep -v 'ib_md'
以 input_2.bin 为例,Fortran 用时 45.75 s ,C 用时 17.48 s 。(还没弄清楚为什么相差这么多)
使用 C 实现参与排名计算分数。